数组a,先单调递增再单调递减,输出数组中不同元素个数。要求:O(1)空间复杂度,不能改变原数组
我的思路的话就是从两头往中间走,i = 0,j = len-1,比较两个数,保证大的那个数不动小的数往中间走,每次比较看数值是否相等,如果相等 i++,j–,否则根据两个值大小确定是 i++ 还是 j–。
House Robber 打家劫舍
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Example 1:
1 | Input: [1,2,3,1] |
维护一个一位数组 dp,其中 dp[i] 表示 [0, i] 区间可以抢夺的最大值,对当前i来说,有抢和不抢两种互斥的选择,不抢即为 dp[i-1](等价于去掉 nums[i] 只抢 [0, i-1] 区间最大值),抢即为 dp[i-2] + nums[i](等价于去掉 nums[i-1])
1 | class Solution { |
拓扑排序
有向无环图该序列必须满足下面两个条件每个顶点出现且只出现一次。若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。当然有向无环图(DAG)才有拓扑排序。

1 |
|
有多个集合,有交集的就合并,输出合并后的结果。
思路很简单,就是对于多个集合进行排序,x 相同 y 小的放前面,否则 x 小的放前面。
然后一遍遍历,我维护当前集合的最右边的值 tempy,如果 tempy 大于下一个集合的初始点的值说明这两个集合有交集,更新 tempy 的值,否则更新 tempy 值为下一个集合的最右边的值。
1 |
|
给一个词典的集合,一组不重复字母,问这些字母可以组成几个词语
先 Hash 一下字母,然后遍历和这个词典的集合,对于每个词语去 Hash 里面查一下,都有就能组成。
时间复杂度是O(集合的词语的长度之和)
有序的数组中找到某一目标值首次出现的下标
给定一个升序的数组,这个数组中可能含有相同的元素,并且给定一个目标值。要求找出目标值在数组中首次出现的下标。
思想:题目给出有序数组,应该想到利用二分查找来做。找到左邻居,使其值加一。利用二分查找,算法复杂度为O(logn)
1 |
|
找到有序数组中某一目标值在数组中的开始下标以及终止下标以及目标值出现的次数,也是同样的结果。
1 |
|
判断回文字符串
将这串数字逆序,然后判断逆序后的数字是否和正序后的数字完全一样,如果完全一样,就是回文。
1 | bool palindrome(char *s) |
判断一个链表是不是回文数
使用 2 个指针,快慢指针各一个,每次慢指针移动一个,快指针移动两个。
当快指针不为 NULL 时候,将慢指针 push 到栈中。
当快指针等于 NULL 时候,说明链表前半部分已经被压入栈中。
每次栈 Top 元素与当前慢指针元素比较,如果不相等则返回 false。如果相等,则栈 Pop,慢指针 ++。
链表奇数或者偶数节点需要判断(如果为奇数那么就删除最后的栈顶)。
1 | //判断单链表是不是回文链表 |
最长回文序列
回文子序列,因为是不连续的肯定是不能直接枚举,那么利用动态规划
我们知道对于任意字符串,如果头尾字符相同,那么字符串的最长子序列等于去掉首尾的字符串的最长子序列加上首尾;如果首尾字符不同,则最长子序列等于去掉头的字符串的最长子序列和去掉尾的字符串的最长子序列的较大者。那么转移方程:
dp[i][j]=dp[i+1][j-1] + 2 if(s[i] == s[j])
dp[i][j]=max(dp[i+1][j],dp[i][j-1]) if (s[i] != s[j])
1 |
|
最长回文子串
1 | string longestPalindrome(string s) |
二叉树的遍历
先序遍历
根节点—>左子树—>右字树
递归遍历
1 | void PreOrder(Tnode* root) |
非递归遍历
先序遍历时,每当我们压入一个结点,我们压入结点前对其进行访问
1 | void PreOrder(Tnode *root) |
中序遍历
左子树—>根节点—>右字树
递归遍历
1 | void InOrder(Tnode* root) |
非递归遍历
中序时我们需要在遍历完左子树后访问根节点,再去遍历右子树
1 | void InOrder(Tnode *root) |
后序遍历
左子树—>右字树—>根节点
递归遍历
1 | void PostOrder(Tnode* root) |
非递归遍历
后序遍历时由于访问完左右子树后才能访问根结点,因此需要将根结点在栈内保留到左右子树被访问后,但同时会出现一个问题,当右子树弹出后遇到根结点又会将右子树结点压入栈中,造成死循环,因此我们需要在定义一个变量last代表最后一个访问的结点,当last与栈顶结点的右子树结点相同时,则不再将右子树结点压入栈中。
1 | void PostOrder(Tnode *root) |
给定中序和前序求层序或者后序
不管是求层序还是后序,主要过程都是一样的都是建树。
首先我们在上面介绍了前序,中序,后序遍历的特性。所以我们基本的思路就是先找到当前树的根节点,然后划分为左子树,右子树,然后进入左子树重复上面的过程,然后进入右子树重复上面的过程。最后就可以还原一棵树了。给个例子介绍一下:
前序遍历:GDAFEMHZ
中序遍历:ADEFGHMZ
画树求法:
- 根据前序遍历的特点,我们知道根结点为
G - 观察中序遍历
ADEFGHMZ。其中root节点G左侧的ADEF必然是root的左子树,G右侧的HMZ必然是root的右子树。 - 观察左子树
ADEF,左子树的中的根节点必然是大树的root的leftchild。在前序遍历中,大树的root的leftchild位于root之后,所以左子树的根节点为D。 - 同样的道理,
root的右子树节点HMZ中的根节点也可以通过前序遍历求得。在前序遍历中,一定是先把root和root的所有左子树节点遍历完之后才会遍历右子树,并且遍历的左子树的第一个节点就是左子树的根节点。同理,遍历的右子树的第一个节点就是右子树的根节点。
1 |
|
给定二叉树,给出S型打印
1 | void S_LevelOrderPrint(TreeNode t) |
N 阶乘末尾0的个数。
要判断末尾有几个0就是判断可以整除几次10。10的因子有5和2,而在0~9之间5的倍数只有一个,2的倍数相对较多,所以本题也就转换成了求N阶乘中有几个5的倍数。
也就是每多出来一个5,阶乘末尾就会多出来一个0,这样n / 5就能统计完第一层5的个数,依次处理,就能统计出来所有5的个数。
1 |
|
给定数组,从数组中取出n个不复用的数的和为sum
深搜
1 | void findd(vector<int>&vr,int pos,int sum,int m,int& res){ |
DP
1 | int main(){ |
求一个无序数组的中位数
利用快排的思想。任意挑一个元素,以该元素为支点,划分集合为两部分,如果左侧集合长度恰为 (n-1)/2,那么支点恰为中位数。如果左侧长度 <(n-1)/2, 那么中位点在右侧,反之,中位数在左侧。 进入相应的一侧继续寻找中位点。
1 | //快排方法,分治思想 |
全排列
1 |
|
36进制加法
1 | package collection; |
n条直线最多把平面分割成几部分?
n条直线最多把平面分成An部分,于是A0=1 A1=2 A2=4
对于已经有n条直线 将平面分成了最多的An块
那么加一条直线 他最多与前n条直线有n个交点 于是被它穿过的区域都被一分为二 那么增加的区域数就是穿过的区域
数 也就是这条直线自身被分成的段数 就是n+1 故 A(n+1) = A(n)+n+1
An = n+(n-1)+...+2+A1 = n(n+1)/2 +1
n条折线分割平面
根据直线分平面可知,由交点决定了射线和线段的条数,进而决定了新增的区域数。当n-1条折线时,区域数为f(n-1)。为了使增加的区域最多,则折线的两边的线段要和n-1条折线的边,即2*(n-1)条线段相交。那么新增的线段数为4*(n-1),射线数为2。但要注意的是,折线本身相邻的两线段只能增加一个区域。
1 | f(n)=f(n-1)+4(n-1)+2-1 |
n个平面分割空间
n个平面最多把空间分成bn个部分
于是b0=1 b1=2 b2=4
对于已经有n个平面 将空间分成了最多的bn块
那么加入一个平面 它最多与每个平面相交 在它的上面就会得到至多n条交线
同时被它穿过的空间区域也被它一分为二 那么增加的区域数仍旧是它穿过的区域数 也就是这个平面自身被直线分割成的块数 就是an于是b(n+1)=bn+an
1 | bn=a(n-1)+b(n-1)=...=a(n-1)+a(n-2)+...+a1+b1 |
数组中唯一出现过一次的数
利用异或的特性:x ^ y ^ x = y ^ x ^ x = y。
1 |
|
一个数组里除了一个数字之外,其他数字出现了n次
我们把这个数分解成二进制,计算出每一位出现1的个数,我们知道如果多次出现的话,1的个数是能够整除这个n,如果发现这个n不能够被 整除的时候,我们就知道那个唯一的数字转换为二进制的时候在这一位上会分解到,我们把这个再转换为十进制的数即可。
1 |
|
找1到n中缺失的数字
数组有序
直接二分时间复杂度为O(logN)。如果中间元素的值和下标相等,那么下一轮查找只需要查找右半边;如果中间元素的值和下标不相等,并且它前面一个元素和它的下标相等,这意味着这个中间的数字正好是第一个值和下标不相等的元素,它的下标就是在数组中不存在的数字;如果中间元素的值和下标不相等,并且它前面一个元素和它的下标不相等,这意味着下一轮查找我们只需要在左半边查找即可。
1 | int getLoseNum(int a[], int left, int right) |
数组无序
1 | /*利用异或运算, |
找1到n中缺失的两个数字
也是采用异或。假设,缺失的数为s1和s2。则s1^s2=1^2^3.....^n^a[0]^a[1]^....a[n-3]。这个式子一目了然,无需多解释。
问题是如何通过这个式子求出s1与s2的值。只要能求出一个值,比如说s1,则s2=s1^(s1^s2)。
s1^s2的值必然不为0,则必然存在一位,s1与s2在此对应位不同。我们就可以按照此对应位是0或者1,将1-n分为两堆,将a[0]-a[n-3]分为两堆。将该为为1的两堆数相异或就能求出缺失的一个数。
举个例子。1-7中缺失3,4。转化为二进制位:011和100。三位都不同,我们用最后一位来判别,将1-n和数组非为两堆。则结果为:
| 标志位(最后一位) | 1 | 0 |
|---|---|---|
| 1-n | 1、3、5、7 | 2、4、6 |
| a[0]-a[n-3] | 1、5、7 | 2、6 |
用标志位为1的数进行异或
1^3^5^7^1^5^7=3。这样就求出了一个缺失数。
1 | void find_missing_number2 (int a[], int size, int& miss1, int& miss2) |
下一个最大数系列
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
在遍历数组的过程中,如果是往后遇到大的数,那就是第一个更大的数,如果一直遇到不断小的数,才会一直找不到,我们可以用一个栈来记录,遇到比栈顶小的数字就放入栈中,遇到比栈顶大的数字就说明这是栈顶数字的下一个更大的数,就将其放在结果数组的对应位置上,栈顶的元素出栈,继续比较新的栈顶的数,如果还是大,那么继续记录,出栈,直到栈顶的数比新数要小,那么就可以将新数入栈了。因为我们要将找到的更大的数放在对应位置上,所以栈中记录的应该是元素位置,而不是具体的数字,但比较的时候还是比较原来的数组中这个位置的数字,此外,因为会出现循环寻找的情况,所以数组我们可能遍历两次。算法的时间复杂度是O(n),空间复杂度也是O(n)。
1 | class Solution { |
输入一个数组,代表每天的温度,求解每天需要经过几天会升温,即需找数组每个元素右边第一个比自己大的数。
利用单调栈性质创建单调递减栈,遍历数组入栈,当将要入栈元素小于栈顶元素时入栈,若要入栈元素大于栈顶元素时,表示入栈元素为所求元素,记录索引,弹出栈顶元素,将此元素压栈,重新比较,一次循环时间复杂度O(n)。
样例输入:[73, 74, 75, 71, 69, 72, 76, 73]
样例输出: [1, 1, 4, 2, 1, 1, 0, 0].
1 | /* |
链表中的下一个更大节点
1 | /** |
未排序的数组第 k 大的数
第一种解法,利用优先队列,维护一个 size == k 的优先队列
1 | class Solution { |
第二种解法:利用快排的思想,就跟无序数组中找中位数一样
1 | class Solution { |
计算数字 n 有多少个二进制 1
利用 n&(n-1) 清除最右边的 1,记录 1 的个数就可以了。
因为从二进制的角度讲,n 相当于在 n - 1 的最低位加上 1。举个例子,8(1000)= 7(0111)+ 1(0001),所以 8 & 7 = (1000)&(0111)= 0(0000),清除了 8 最右边的 1(其实就是最高位的 1,因为 8 的二进制中只有一个1)。再比如7(0111)= 6(0110)+ 1(0001),所以7 & 6 = (0111)&(0110)= 6(0110),清除了7的二进制表示中最右边的 1(也就是最低位的 1)
1 | int BitCount2(unsigned int n) |
由上面的解法,我们可以判断一个数是 2 的幂数的最快方法是
1 | if(n&(n-1)) |
1-n 中有多少个二进制 1
我觉得 for 一遍循环,就很快了差不多 O(n) 的时间复杂度。
找出只由 a,b,c 组成的字符串中包含 abc 的个数
给个样例,abccc 可以找到 3 个 abc。
思路就是
一个数组中只有0,1,2三个元素,进行排序,要求时间复杂度为O(n)
设置三个标记指针,pos0,pos2,cur ,令 pos0 从前往后遍历,指向第一个非 0 的位置,pos2 从后往前遍历,指向第一个非 2 的位置
然后 cur 从 pos0 开始往后遍历:
遇到 0 就和pos0交换,pos0++;
遇到 1 什么也不做;
遇到 2 就和 pos2 交换,pos2 向前滑动到下一个非2的位置,交换后还要重新检查 cur 的值;
直到 cur 与 pos2 相遇。
1 | nt main(){ |
输出一个递增排序数组的旋转数组中的最小元素 或者 下标
1 | int find_min_num(const int *arr, size_t n) |
求二叉树中节点的差的最大值
其实就是求出二叉树中结点的最大值和最小值,相减就是结果。
1 | typedef struct node{ |
实现pow函数求x的y次方
1 | class Solution { |
x 的平方根
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
1 | 输入: 8 |
1 | class Solution { |
二维坐标系,有一组点,若一个点的x y都小于某个点,那么这个点就包含它,它的价值是它包含的点的个数,求最大价值的点的价值? (提示可以先排序)
一个模拟Windows窗体管理的类,(x1,y1)和(x2,y2)分别是窗体左上角和右下角像素点座标有很多个矩形,求覆盖的总面积
Java 判断字符串是否是网址
1 | public static boolean isHttpUrl(String urls) { |
3个线程顺序打印数字
问题:启动3个线程A、B、C,使A打印0,然后B打印1,然后C打印2,A打印3,B打印4,C打印5,依次类推。
思路:每个线程给定一个编号,每个线程判断当前是否已经轮到自己打印:如果没轮到,就wait等待;如果轮到,则打印当前数字,并唤醒其他线程。
判断是否已经轮到自己打印:
每个线程给定一个编号N,N从0开始;
使用一个全局变量记录当前需要打印的数字C,C从0开始,每次打印之后加1;
线程数量M;
判断逻辑:C%M ==N
1 | public class PrintSequenceThread implements Runnable { |
从左(右)边看二叉树
二叉树的层次遍历,每层按照从左向右的顺序依次访问节点(每一层取最(左)右边的节点)。
1 | /** |
给定一个数组,与数字m最接近的k个数
在排序数组中找最接近的K个数
Java List转Tree
细节实现看:
1 | https://blog.csdn.net/MassiveStars/article/details/53911620 |
字符串排序,要求O(n)
我们知道字符 char 的范围是 -128-127,开一个 255 大小的数组排序。一次遍历字符串,对应的数组位置值 ++
然后一遍遍历输出即可。
不相邻和最大
对于一个给定的数组,在其中选取其子数组,要求相邻的元素不能选取,且要保证选出的子数组元素和最大。输入数组长度及其元素,输出所选子数组的和。
1 | 测试输入 |
为了让子数组和最大,应该尽可能让它包含更多的元素,并且相邻元素不能选取,所以选取的任意两个数字之间最多间隔两个数,因为假设如果间隔了三个而子数组和最大,那么最中间的那个数一定可以选中,此时子数组和也一定比之前更大,产生矛盾。由此可见,本题只需要分析连续的三个元素的关系即可。
按照第 i 个元素是否被选取,前 i 个元素的和要么与前 i−1 个元素的和相同(不选取),要么是前 i−2 个元素的和加上此第 i 个元素(选取),这两种情况取最大。这很容易通过递归实现出来,也可以使用动态规划实现。要用动态规划,子问题的选取需要具有无后效性,即前 i 个元素的选取只能和之前的选取有关,和未来的情况无关。对于数组array[i],i=0∼n−1,定义 s[i] 表示前 i 个元素的最大和,则递归式为
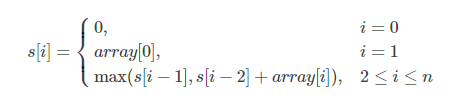
1 | import java.util.Scanner; |
那如果是在一个环上呢:看解析
一个环路加油站,是否能走一圈
城市的环形路有n个加油站,第i个加油站的油量用gas[i]来表示,你有如下的一辆车:
它的油缸是无限量的,初始是空的
它从第i个加油站到第i+1个加油站消耗油量为cost[i]
现在你可以从任意加油站开始,路过加油站可以不断的加油,问是否能够走完环形路。如果可以返回开始加油站的编号,如果不可以返回-1。
思路:假设起始的加油站是src,最后一个加油站是dst,在从src出发达到下一个加油站的油剩下sum。那么需要能够从src到dst中的每个点的油剩余量都有>=0。
假设从src出发,某点的油量sum<0,那么我们就从src-1站出发,此时达到这个“某点”的油量剩余就是sum += gas[src-1]-cost[src-1],此时的dst将是src -1 再 -1。
1 | class Solution { |
堆的中位数算法
桌子上有一副牌,循环进行以下操作:(1)将顶部的牌放到桌上 (2)再将当前顶部的牌放入底部,循环到所有牌都放到桌上,假设最后放到桌子上的牌顺序是 13 12 11 …. 1,问初始的牌堆是怎么放的
找到数组中的两个数 A 和 B,要求将 A 和 B 交换之后自区间和是最大的,输出 A、B 和 最大自区间和
LeetCode 4 两个排序数组的中位数(数组、二分查找、分治法)
Leetcode 400 找到第 N 位
Find the nth digit of the infinite integer sequence 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, …
Note:
n is positive and will fit within the range of a 32-bit signed integer (n < 231).
Example 1:
1 | Input: |
Example 2:
1 | Input: |
自然数序列看成一个长字符串,问我们第N位上的数字是什么。那么我们首先来分析自然数序列和其位数的关系,前九个数都是1位的,然后10到99总共90个数字都是两位的,100到999这900个数都是三位的,那么这就很有规律了,我们可以定义个变量cnt,初始化为9,然后每次循环扩大10倍,再用一个变量len记录当前循环区间数字的位数,另外再需要一个变量start用来记录当前循环区间的第一个数字,我们n每次循环都减去len*cnt (区间总位数),当n落到某一个确定的区间里了,那么(n-1)/len就是目标数字在该区间里的坐标,加上start就是得到了目标数字,然后我们将目标数字start转为字符串,(n-1)%len就是所要求的目标位。
1 | class Solution { |
Reverse Nodes in k-Group 每k个一组翻转链表
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list.
k is a positive integer and is less than or equal to the length of the linked list. If the number of nodes is not a multiple of k then left-out nodes in the end should remain as it is.
1 | Example: |
实际上是把原链表分成若干小段,然后分别对其进行翻转,那么肯定总共需要两个函数,一个是用来分段的,一个是用来翻转的。
pre 和 next 分别指向要翻转的链表的前后的位置,然后翻转后 pre 的位置更新到如下新的位置

以此类推,只要 cur 走过k个节点,那么 next 就是 cur->next,就可以调用翻转函数来进行局部翻转了,注意翻转之后新的 cur 和 pre 的位置都不同了,那么翻转之后,cur 应该更新为 pre->next,而如果不需要翻转的话,cur 更新为 cur->next。
1 | class Solution { |
矩阵中的最长递增路径
给定一个整数矩阵,找出最长递增路径的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
1 | 示例 1: |
引入动态规划思想,记忆化搜索,用一个数组 len[][] 记录任意点的递增路径长度,再利用一个 visited[][] 数组记录当前位置是否遍历过,如果已经处理过该点,那么直接返回该点对应的路径长度即可。
1 | class Solution { |
求数组中区间中最小数*区间所有数和的最大值
给定一段数组,求每个区间的最小值乘这段区间的和,输出每个区间得到的最大值。
1 | 样例输入:[1 2 6],可能有以下几种情况: |
以数组中每一个值为最小值,假设这个最小值为num[k], 分别找到以该值num[k]为最小值,数组最左边的小于该值的下标i,和数组最右边的小于该值的下标j, 则区间num[i+1,j-1]为以num[k]为最小值所能达到的最大区间,则此区间能达到的最大值为 num[k]*Sum(i+1,j-1),其中 Sum 函数为数组中区间[i+1,j+1]的所有数的和
1 | public class test { |
LeetCode 31. 下一个排列
实现获取下一个排列函数,这个算法需要将数字重新排列成字典序中数字更大的排列。
如果不存在更大的排列,则重新将数字排列成最小的排列(即升序排列)
以一个例子来分析,给定325421,求其下一个比它大的数,怎么办呢?我们应该从最低位开始,1->2->4->5,这一段是升序的,也就是5421已经是最大数,不存在比它大的组合,我们继续找,1->2->4->5->2,出现降序这个位置就是我们要找的关键点,只需要将2与其后的数字中的(1,2,4,5)比它大的最小数,也就4替换,然后再将后面的数(1,2,2,5)升序排列便可得到下一个数,过程为:325421->345221->345122
解法:从后往前遍历数组,找到当前节点右侧第一个比当前节点大的数,交换他们,然后使当前右侧有序即可。
假设数组nums长度为n(从0开始编号),数组中nums[i]到第nums[n-1]逆序(降序排列),且nums[i-1]<nums[i],则下一个全排列时只需要考虑nums[i-1]到nums[n-1]即可,在i-1 右侧找到第一个大于nums[i-1] 的数,交换他们顺序,则后面升序排列就是最小的数,即下一个全排列。
1 | class Solution { |
划分为k个相等的子集
给定一个整数数组 nums 和一个正整数 k,找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。
1 | 示例 1: |
先求出平均数avg,假如平均数avg不为整数,也就是说数组的数字总和不能平均的分为k份,那么直接返回false。
创建一个布尔数组flag,来记录nums数组中数字的状态(已用还是未用), temp 初始为avg ,temp的作用为记录当前子集的数字总和,当temp等于0时,当前这个子集也就可以确定。index是用来记录遍历数组时从哪个位置开始遍历,以防将前面的数字重新计算。
当k个子集全部求解完,返回true,如果一直求解不出,则返回false。当temp = 0 的时候,也就是新一个子集求解完,那么继续求解下一个子集,k-1,temp重新置为avg;当temp != 0 时,就是子集还未求解完,那么继续求解子集,继续从数组中取数字,递归求解
1 | class Solution { |